CIFAR10Partitioner#
我们为CIFAR10提供了6种预定义的数据划分方案。我们根据以下参数来划分CIFAR10:
targets是数据集对应的标签num_clients指定划分方案中的client数量balance指不同client的数据样本数量全部相同的联邦学习场景partition指定划分方法的名字unbalance_sgm是用于非均衡划分的参数num_shards是基于shards进行non-IID划分需要的参数dir_alpha是划分中用到的Dirichlet分布需要的参数verbose指定是否打印中间执行信息seed用于设定随机种子
可以通过用不同的参数组合来实现不同的数据划分方案:
balance=None: 无需提前指定每个client的样本数量partition="dirichlet":Yurochkin et al. [6] 和 Wang et al. [8] 中用的non-IID划分。该划分方法需指定dir_alpha。partition="shards":FedAvg [3] 中用到的non-IID方法。更多细节参考fedlab.utils.dataset.functional.shards_partition()。该方法需指定num_shards。
balance=True: “balance” 指不同client拥有相同样本数量的联邦学习场景。更多细节参考fedlab.utils.dataset.functional.balance_partition()。该划分方法出自 Acar et al. [5]。partition="iid":给定每个client的样本数量,从完整数据集中均匀随机地选择样本。partition="dirichlet":更多细节参考fedlab.utils.dataset.functional.client_inner_dirichlet_partition()。在该划分方法中dir_alpha需被指定。
balance=False:”Unbalance” 指不同client拥有不同样本数量的联邦学习场景。在非均衡方法中,不同client的样本数量用方差为unbalanced_sgm的Log-Normal分布生成。当unbalanced_sgm=0时,划分是均衡的。该划分方法源自 Acar et al. [5]。partition="iid":给定每个client的样本数量,从完整数据集中均匀随机地选择样本。partition="dirichlet":给定每个client的样本数量,从Dirichlet分布中抽样得到每个类样本的比例。该划分方法需指定dir_alpha。
六种预定义的划分方案可以总结为:
Hetero Dirichlet (non-iid)
Shards (non-iid)
均衡IID(IID)
非均衡IID(IID)
均衡Dirichlet(non-IID)
非均衡Dirichlet(non-IID)
现在来介绍如何在一个拥有100个client的联邦学习场景中,用这些预定义的方案对CIFAR10进行划分,并给出每种划分方案的统计结果可视化。
首先,导入相关的包以及基本设定:
import torch
import torchvision
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
import sys
from fedlab.utils.dataset.partition import CIFAR10Partitioner
from fedlab.utils.functional import partition_report, save_dict
num_clients = 100
num_classes = 10
seed = 2021
hist_color = '#4169E1'
第二步,我们从 torchvision 中加载CIFAR10数据集:
trainset = torchvision.datasets.CIFAR10(root="../../../../data/CIFAR10/",
train=True, download=True)
Hetero Dirichlet#
执行数据划分:
hetero_dir_part = CIFAR10Partitioner(trainset.targets,
num_clients,
balance=None,
partition="dirichlet",
dir_alpha=0.3,
seed=seed)
hetero_dir_part.client_dict 是一个字典结构:
hetero_dir_part.client_dict= { 0: indices of dataset,
1: indices of dataset,
...
100: indices of dataset }
为了可视化以及检查划分结果,我们可以为当前划分生成划分报告,并将其保存于csv文件:
csv_file = "./partition-reports/cifar10_hetero_dir_0.3_100clients.csv"
partition_report(trainset.targets, hetero_dir_part.client_dict,
class_num=num_classes,
verbose=False, file=csv_file)
这里生成的报告大概为:
Class frequencies:
client,class0,class1,class2,class3,class4,class5,class6,class7,class8,class9,Amount
Client 0,0.170,0.00,0.104,0.00,0.145,0.004,0.340,0.041,0.075,0.120,241
Client 1,0.002,0.015,0.083,0.003,0.082,0.109,0.009,0.00,0.695,0.00,863
Client 2,0.120,0.759,0.122,0.00,0.00,0.00,0.00,0.00,0.00,0.00,526
...
可以用 csv.reader() 或 pandas.read_csv() 来解析。
hetero_dir_part_df = pd.read_csv(csv_file,header=1)
hetero_dir_part_df = hetero_dir_part_df.set_index('client')
col_names = [f"class{i}" for i in range(num_classes)]
for col in col_names:
hetero_dir_part_df[col] = (hetero_dir_part_df[col] * hetero_dir_part_df['Amount']).astype(int)
现在选出前10个client用于类分布的条形图:
hetero_dir_part_df[col_names].iloc[:10].plot.barh(stacked=True)
plt.tight_layout()
plt.xlabel('sample num')
plt.savefig(f"./imgs/cifar10_hetero_dir_0.3_100clients.png", dpi=400)

我们可以检查一下所有client的样本数量统计结果:
clt_sample_num_df = hetero_dir_part.client_sample_count
sns.histplot(data=clt_sample_num_df,
x="num_samples",
edgecolor='none',
alpha=0.7,
shrink=0.95,
color=hist_color)
plt.savefig(f"./imgs/cifar10_hetero_dir_0.3_100clients_dist.png", dpi=400, bbox_inches = 'tight')

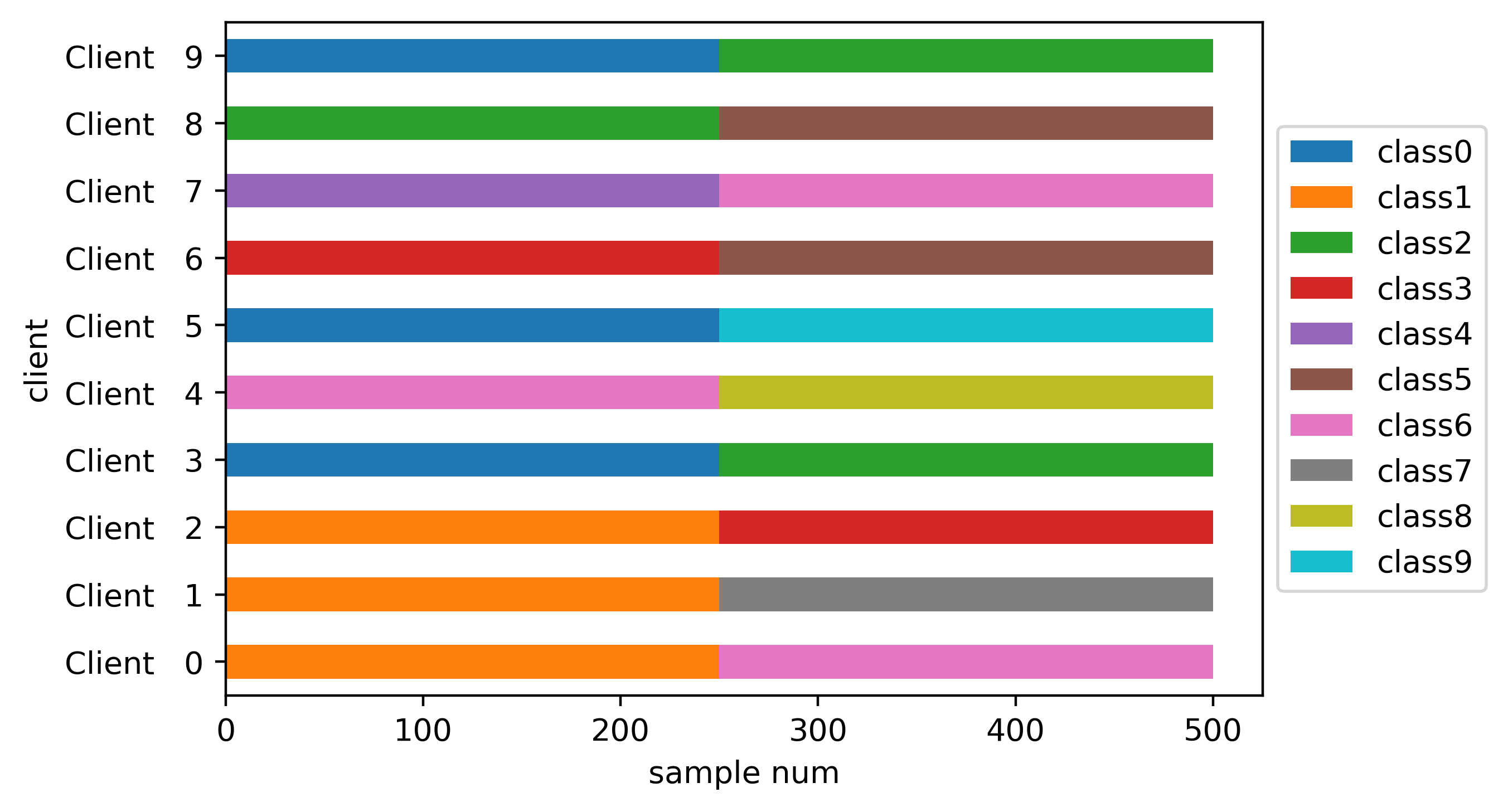
基于Shards的划分#
执行数据划分:
num_shards = 200
shards_part = CIFAR10Partitioner(trainset.targets,
num_clients,
balance=None,
partition="shards",
num_shards=num_shards,
seed=seed)
类分布的条形图:
均衡IID划分#
执行数据划分:
balance_iid_part = CIFAR10Partitioner(trainset.targets,
num_clients,
balance=True,
partition="iid",
seed=seed)
类分布的条形图:

非均衡IID划分#
执行数据划分:
unbalance_iid_part = CIFAR10Partitioner(trainset.targets,
num_clients,
balance=False,
partition="iid",
unbalance_sgm=0.3,
seed=seed)
类分布的条形图:

client上的样本数量统计结果:

均衡Dirichlet划分#
执行数据划分:
balance_dir_part = CIFAR10Partitioner(trainset.targets,
num_clients,
balance=True,
partition="dirichlet",
dir_alpha=0.3,
seed=seed)
类分布的条形图:

非均衡Dirichlet划分#
执行数据划分:
unbalance_dir_part = CIFAR10Partitioner(trainset.targets,
num_clients,
balance=False,
partition="dirichlet",
unbalance_sgm=0.3,
dir_alpha=0.3,
seed=seed)
类分布的条形图:

client上的样本数量统计结果:

备注
CIFAR10Partitioner 的完整使用例子,请见FedLab benchmarks的 数据集部分.
SubsetSampler#
By using torch’s sampler, only the right part of the sample is taken from the overall dataset.
from fedlab.utils.dataset.sampler import SubsetSampler
train_loader = torch.utils.data.DataLoader(trainset,
sampler=SubsetSampler(indices=partition[client_id], shuffle=True),
batch_size=batch_size)
There is also a similar implementation of directly reordering and partition the dataset, see fedlab.utils.dataset.sampler.RawPartitionSampler for details.
In addition to dividing the dataset by the sampler of torch, dataset can also be divided directly by splitting the dataset file. The implementation can refer to FedLab version of LEAF.